What Are the Essential MLOps Practices for Production AI?
MLOps (Machine Learning Operations) is the discipline of deploying, monitoring, and maintaining ML models in production. The five essentials: version control for models and data, automated CI/CD pipelines for model deployment, drift detection to catch degrading performance, automated retraining triggers, and real-time monitoring dashboards. Gartner reports that 85% of AI projects fail to reach production — MLOps is the difference between a successful demo and a system that delivers value at scale.
Talk to our ML engineering team about operationalising your AI models.
CI/CD for Machine Learning
Traditional CI/CD deploys code. ML CI/CD deploys code, data, and models — a three-dimensional versioning challenge.
Code pipeline: Standard Git workflow. Feature branches, pull requests, automated tests. Every model training script and inference endpoint is version-controlled.
Data pipeline: Data versioning (DVC or MLflow) tracks which training data produced which model. When data changes, the pipeline automatically retrains and validates.
Model pipeline: Every trained model gets a unique version, associated metrics (accuracy, F1, AUC), and a comparison against the production model. Only models that beat the current production model get promoted.
Deployment: Canary releases — the new model serves 5% of traffic initially. If metrics hold, traffic ramps to 100% over 48 hours. If metrics degrade, automatic rollback to the previous version.
Drift Detection
Models degrade over time. Three types of drift to monitor:
Data drift: Input data distribution changes. Example: a predictive maintenance model trained on summer data performs poorly in winter because temperature patterns shift. Detection: Kolmogorov-Smirnov test or Population Stability Index on input features.
Concept drift: The relationship between inputs and outputs changes. Example: a defect detection model degrades because a new supplier's materials have different visual characteristics. Detection: monitor prediction confidence and error rates over time.
Prediction drift: Output distribution changes even if inputs look stable. Detection: compare prediction distributions week-over-week.
Retraining Triggers
Set automated retraining when:
- Prediction accuracy drops below threshold (e.g., < 90%)
- Data drift score exceeds threshold (e.g., PSI > 0.2)
- New labelled data accumulates (e.g., 1,000 new samples)
- Calendar-based (e.g., monthly for seasonal models)
Retraining must be automated but deployment must be gated — no model goes to production without human approval on the metrics comparison.
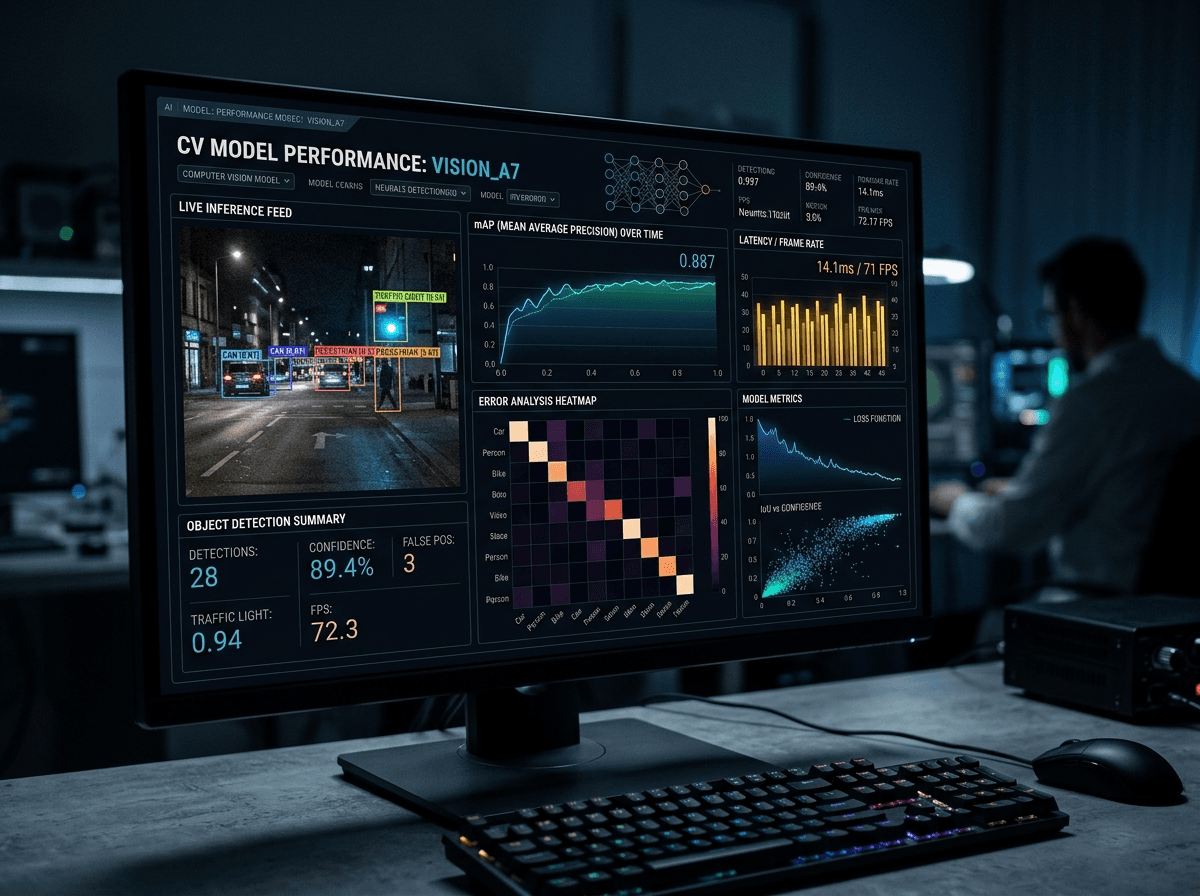
Monitoring Dashboard
Every production model needs a live dashboard showing:
- Prediction volume (requests/second)
- Latency (P50, P95, P99)
- Error rate (4xx, 5xx)
- Model accuracy (vs validation set, refreshed weekly)
- Drift scores (data, concept, prediction)
- Feature importance stability
Frequently Asked Questions
How many ML engineers do I need for MLOps?
A single ML engineer can manage MLOps for 3-5 production models. Beyond that, you need dedicated MLOps infrastructure. Ontario companies with 1-2 models often outsource MLOps to our AI consulting division rather than hiring a full-time MLOps engineer.
What tools do you recommend for MLOps in 2026?
MLflow for experiment tracking and model registry. DVC for data versioning. GitHub Actions or GitLab CI for pipeline automation. Prometheus + Grafana for monitoring. Kubernetes for model serving. This stack is open-source, battle-tested, and runs on Canadian cloud infrastructure.
How do I know if my model needs retraining vs replacement?
If retraining on fresh data restores accuracy to original levels, retrain. If accuracy plateaus despite fresh data, the model architecture or feature engineering needs revision — that is replacement, not retraining.
Droz Technologies deploys and operates production ML systems for Ontario enterprises. Talk to our ML engineering team about your MLOps strategy.
Ready to apply this?